


本课程旨在帮助具有一定文本到图像合成经验的专业人士掌握 Stable Diffusion、SDXL 和 ComfyUI,从而实现精细、专业的成果。您将学习如何有效高效地使用这些工具,并将它们调整到您的工作需求和偏好。通过本课程,您将能够充分利用 ComfyUI 的高效性和灵活性,产生始终如一的可靠结果,逐渐与行业最佳水平接轨。 Stabl Diffusion 是一种潜在的文本到图像扩散模型,能够根据任何文本输入生成逼真的图像。它基于将扩散过程逆转的思想,逐渐将图像转化为随机噪音。通过应用神经网络在文本上的条件反向步骤,Stable Diffusion 可以从噪音中恢复原始图像。SDXL 是 Stable Diffusion 的最新和最先进版本,利用了更大更强大的 UNet 主干,具有更多的注意力块和更大的交叉注意力上下文。SDXL 可以以几乎任何艺术风格生成高质量的图像,是最适合逼真效果的开放模型。它还可以处理诸如手部、文本和空间布局等具有挑战性的概念。ComfyUI 支持 SD1.x、SD2.x 和 SDXL 模型,以及独立的VAEs和CLIP模型。ComfyUI 还提供许多功能,如嵌入、文本反演、Loras、超网络、工作流的加载和保存,以及图像控制。Generative AI Mastery with ComfyUI SDXL and Stable Diffusion
由Pixovert工作室创建
MP4 |视频:h264,1280×720 |语言:英语+中英文字幕(云桥网络 机译)|课程时长:(2小时15分钟)
Use the Speed and Flexibility to ComfyUI to create Spectacular Works of Art from Professional Workflows
What you’ll learn
Master the art of Prompt Engineering to Provide Professional, reliably consistent results
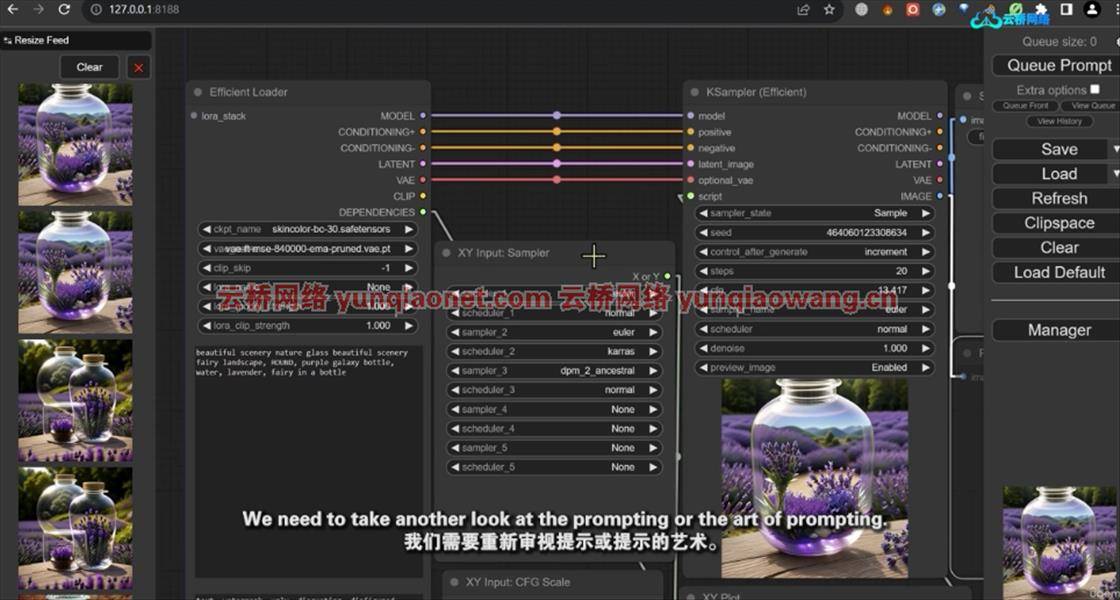
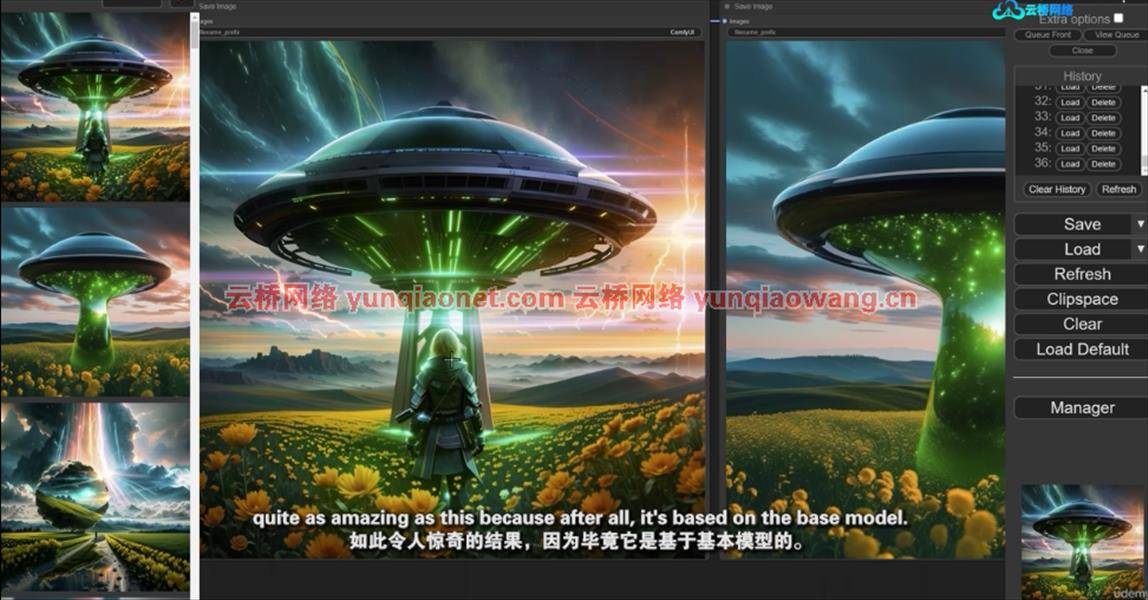
Create Huge Landscapes using built-in features in Comfy-UI – for SDXL or earlier versions of Stable Diffusion
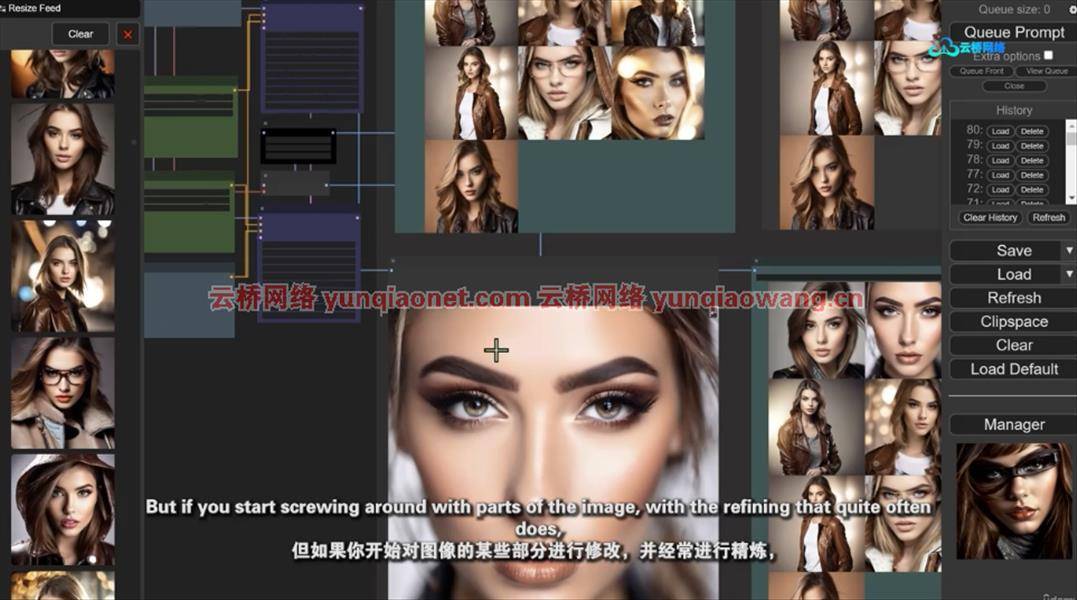
Produce beautiful portraits in SDXL
Use the Speed and Efficiency of ComfyUI to do batch processing for more effective cherry picking
Understand the dualism of the Classifier Free Guidance and how it affects outputs
Requirements
The ability to setup and run Stable Diffusion through the ComfyUI interface
A powerful consumer PC or Professional Workstation with a Stable Diffusion capable GPU
The desire to achieve reliably professional diffusions
Attention to detail. Attention to Process
Genuine interest and skill in critiquing and evaluativing Generative AI outputs

Description
Do you already know how to create stunning images from text prompts? Have you have started to unleash your creativity and produced amazing art using the power of artificial intelligence? Do you want to go the next step and step up to consistently producing professional results? If so, then this course is for you!This course is designed for professionals who already have some experience with text-to-image synthesis and want to take their skills to the next level. You will learn how to master Stable Diffusion, the state-of-the-art latent text-to-image diffusion model that can generate photo-realistic images given any text input. You will also learn how to master SDXL, the latest and most advanced version of Stable Diffusion, which can handle challenging concepts and produce images of high quality in virtually any art style. And you will learn how to master ComfyUI, the robust and modular Stable Diffusion GUI and backend that enables you to design and execute advanced Stable Diffusion pipelines using a graph and nodes-based interface.By taking this course, you will also be able to fine-tune the parameters and the workflows to your needs and preferences, as well as write creative and high-quality prompts that can produce amazing results. You will also gain a deeper understanding of the underlying principles and techniques of text-to-image synthesis, latent diffusion models, and image refinement techniques.This course is not for beginners who need introductory learning. This course is for professionals who want to master Stable Diffusion, SDXL and ComfyUI and achieve polished, professional outcomes. If you are ready to take your text-to-image synthesis skills to the next level, then enroll in this course today!Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input. It is based on the idea of reversing the diffusion process, which gradually transforms an image into random noise. By applying the reverse steps with a neural network conditioned on text, Stable Diffusion can recover the original image from the noise.SDXL is the latest and most advanced version of Stable Diffusion, which leverages a larger and more powerful UNet backbone with more attention blocks and a larger cross-attention context. SDXL can generate images of high quality in virtually any art style and is the best open model for photorealism. It can also handle challenging concepts such as hands, text, and spatial arrangements.ComfyUI supports SD1.x, SD2.x and SDXL models, as well as standalone VAEs and CLIP models. ComfyUI also offers many features such as embeddings, textual inversion, Loras, hypernetworks, loading and saving workflows, and image control.The goal of this course is to help you achieve polished, professional outcomes with Stable Diffusion, SDXL and ComfyUI. You will learn how to use these tools effectively and efficiently, as well as how to fine-tune them to the demands of your work and your preferences. By the end of this course, you will be able to get the most out of the efficiency and flexibility of ComfyUI to produce reliably consistent results that begin to match the best in the industry.
1、登录后,打赏30元成为VIP会员,全站资源免费获取!
2、资源默认为百度网盘链接,请用浏览器打开输入提取码不要有多余空格,如无法获取 请联系微信 yunqiaonet 补发。
3、分卷压缩包资源 需全部下载后解压第一个压缩包即可,下载过程不要强制中断 建议用winrar解压或360解压缩软件解压!
4、云桥网络平台所发布资源仅供用户自学自用,用户需以学习为目的,按需下载,严禁批量采集搬运共享资源等行为,望知悉!!!
5、云桥网络-CG数字艺术学习与资源分享平台,感谢您的关注与支持!

评论(0)